| O
Sistema NeuroTexto
O NeuroTexto é um sistema ICR do tipo
off-line cuja tecnologia vem sendo
inteiramente desenvolvida no LabIC (Laboratório
de Inteligência Computacional) do NCE-UFRJ
e sua finalidade é processar formulários
de concursos de forma automática e eficiente.
O sistema já se encontra em fase de protótipo
e apresentando resultados bastante animadores.
O NeuroTexto é constituído
de várias fases que vão desde
a captura e digitalização da imagem
do formulário até a crítica
do resultado do reconhecimento pelo usuário
e geração da base de dados alvo.
Cada fase corresponde a um módulo do
sistema que compreende funções
bem específicas. A estrutura do sistema
bem como uma breve explicação
de cada módulo são apresentados
a seguir.
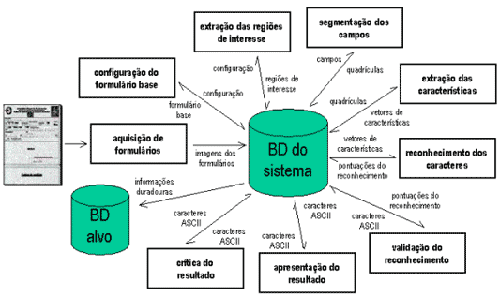 |
Módulos
constituintes do sistema NeuroTexto |
Aquisição de formulários:
é o módulo responsável
pela captura do formulário em seu formato
físico e o armazenamento de sua imagem
em formato digital.
Configuração do formulário
base: neste módulo o usuário elege
um formulário como sendo a base e define
em cima dele as posições das regiões
de interesse (campos, marcadores, códigos
de barras, assinaturas, etc.), que serão
as referências para a extração
das regiões de interesse dos outros formulários.
Extração das Regiões de
Interesse: a partir das configurações
estabelecidas no formulário base, o módulo
de extração das regiões
de interesse se encarrega de localizar e extrair
estas regiões da imagem de cada um dos
formulários adquiridos.
Segmentação dos campos: dentre
as regiões de interesse extraídas,
apenas as que devem ser reconhecidas são
endereçadas ao módulo de segmentação,
para que se obtenha apenas imagens de caracteres
isolados.
Extração das características:
é o módulo encarregado de extrair
da imagem de cada caractere um conjunto de características
numéricas que representam a “assinatura”
daquele caractere.
Reconhecimento dos caracteres: recebe como entrada
as “assinaturas” dos caracteres
e devolve como saída, para cada caractere,
um conjunto de 26 valores, se este for uma letra,
ou 10 valores, se for um algarismo. Cada um
destes valores é interpretado como uma
pontuação que associa o caractere
à classe correspondente.
Validação do reconhecimento: sua
finalidade é dar confiabilidade ao resultado
do reconhecimento das letras por meio da aplicação
de técnicas de correção
de erros, modificando ou confirmando o resultado
do reconhecimento de uma letra.
Apresentação do resultado: é
o módulo que exibe ao usuário
do sistema os resultados do reconhecimento e
da validação, para que compare
visualmente os resultados com as respectivas
imagens dos campos e realize as eventuais correções.
Crítica do resultado: estabelece regras
para determinados campos que, quando cumpridas,
eliminam inconsistências que se devem,
principalmente, a erros de preenchimento cometidos
pelos candidatos e não mais a erros cometidos
pelo sistema.
Banco de dados do sistema: é responsável
pela transferência de informações
de um módulo para outro e, ao final de
um ciclo de funcionamento do sistema, armazena
todas as informações produzidas
por cada módulo. Parte destas informações
é de interesse do contratante do serviço
e é enviada ao banco de dados alvo, enquanto
o restante é eliminado.
Banco de dados alvo: armazena as informações
que devem ser enviadas ao contratante do serviço,
ou seja, as imagens dos formulários,
as fotografias dos candidatos, as assinaturas
e, evidentemente, os resultados do processo
de reconhecimento.
Conclusões
Mesmo com níveis de desempenho considerados
satisfatórios, a pesquisa em reconhecimento
de caracteres está longe de ser esgotada.
Até agora, o sucesso dos sistemas OCR
não pôde ser alcançado pelos
sistemas ICR, e mesmo os OCR’s ainda apresentam
algumas limitações. Limitações
estas que estão presentes tanto nas técnicas
de tratamento e de extração de
informações dos caracteres quanto
nas próprias técnicas de reconhecimento.
Dentre os sistemas ICR, o bom desempenho está
limitado ao reconhecimento de caracteres isolados.
Os ICR’s para escrita cursiva, tanto do
tipo on-line quanto do tipo off-line,
ainda estão longe de apresentar resultados
satisfatórios e, por isso, este desafio
ainda ocupará as mentes dos entusiastas
por um bom tempo.
|



