1. Introdução
Em uma aplicação Orientada a Objetos
(OO) a lógica da aplicação
é distribuída por uma rede de
objetos. Usualmente estes objetos residem em
uma camada chamada de camada de domínio.
Tradicionalmente, existem três formas
principais de organizar os objetos na camada
de domínio:
a) Roteiros de Transação:
Toda a lógica de uma transação
ou de um caso de uso é encapsulada em
um único objeto que valida os dados,
processa esses dados, faz consultas e atualiza
o banco de dados, etc. Um problema em particular
com os Roteiros de Transação é
que qualquer código comum às transações
tende a ser duplicado. Apesar de constituir
uma arquitetura “pobre” para um
sistema orientado a objetos, seu uso não
deve ser desprezado em sistemas simples onde
o tempo de desenvolvimento é um dado
crítico.
b) Módulos Tabela: Neste
modelo, cada tabela no banco de dados é
representada por um objeto na camada de domínio.
Este objeto encapsula todo o código SQL
necessário para recuperar, inserir e
atualizar dados da tabela. Cada módulo
tabela é responsável por uma única
tabela e não conhece a estrutura das
demais tabelas. Seu uso deve ser considerado
quando o modelo conceitual é muito parecido
com o esquema do banco de dados. Um Módulo
Tabela é uma solução simples
para organizar a lógica do domínio,
no entanto, você não pode usar
várias das técnicas disponíveis
para organizar a lógica de domínio
em aplicações complexas tais como
herança, estratégias e outros
padrões OO.
c) Modelo de Domínio:
Cada instância de um conceito no domínio
da aplicação é representada
por um objeto na camada de domínio. Assim,
teríamos um objeto para cada aluno de
uma universidade, um objeto para cada exemplar
de uma biblioteca, etc. Quanto mais complexa
a lógica de uma aplicação,
maiores são os benefícios na utilização
de um Modelo de Domínio. Diversas técnicas
estão disponíveis que permitem
lidar com lógica complexa de uma forma
organizada [Gamma et al.]. Os inconvenientes
no uso de um Modelo de Domínio vem da
complexidade do uso e da complexidade da camada
de dados.
Estudaremos neste artigo os dois modelos de
maior complexidade: Módulos Tabela e
Modelos de Domínio.
2. Camadas
A criação de camadas é
uma das técnicas mais comuns que os projetistas
usam para quebrar a complexidade de um sistema
de software. Um exemplo conhecido são
as redes de computadores: o serviço FTP
consiste em uma camada sobre TCP o qual, por
sua vez, é uma camada sobre IP, que por
sua vez está sobre a ethernet.
Neste esquema, a camada em um nível mais
alto usa os serviços disponibilizados
pela camada imediatamente inferior, mas esta
ignora a existência da camada mais alta.
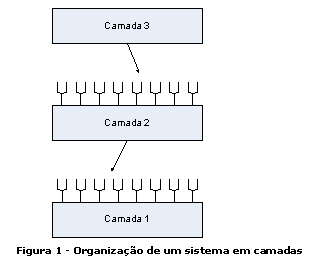
Além disso, cada camada normalmente esconde
suas camadas mais baixas das camadas acima (Figura
1). Assim, a camada 3 usa os serviços
da camada 2 a qual usa os serviços da
camada 1, mas a camada 3 ignora a existência
da camada 1.
Dividir um sistema em camadas tem uma série
de benefícios importantes:
· Você pode compreender uma única
camada como um todo coerente sem saber muito
sobre as outras camadas. Por exemplo, você
pode compreender como construir um serviço
FTP sobre TCP sem conhecer os detalhes de como
funciona o protocolo ethernet.
· Você pode substituir uma camada
por uma implementação alternativa,
desde que ela ofereça os mesmos serviços
em sua interface.
· Você minimiza as dependências
entre as camadas. Se houver alterações
na interface da camada 1, estão alterações
serão sentidas pela camada 2, mas não
afetarão a camada 3.
· Uma mesma camada pode ser usada por
muitos serviços diferentes na camada
imediatamente acima. Usando ainda o exemplo
das redes de computadores, TCP/IP é usado
por FTP, telnet, SSH e HTTP.
3. A Evolução das Camadas
A noção de camadas se tornou mais
visível nos anos 90 com o advento dos
sistemas cliente-servidor. Estes eram sistemas
em duas camadas: O cliente mantinha a interface
com o usuário e a lógica da aplicação
enquanto que o servidor, normalmente, era um
banco de dados relacional. Ferramentas comuns
para o lado cliente eram, por exemplo, VB e
Delphi. Estas ferramentas tornavam particularmente
fácil criar aplicações
que faziam uso intensivo de dados, na medida
que elas disponibilizavam componentes visuais
que trabalhavam com SQL. Assim, você podia
criar uma tela arrastando controles para uma
área de desenho e, então, usando
páginas de propriedades, conectar os
controles ao banco de dados.
Se a aplicação tivesse somente
de exibir e fazer atualizações
simples em dados relacionais, estes sistemas
cliente-servidor funcionavam bem. O problema
surgia com a lógica de domínio
complexa: regras de negócio, validações,
cálculos, e assim por diante. Normalmente,
as pessoas escreviam essa lógica no cliente
(clientes gordos), embutindo-a diretamente nas
telas da interface com o usuário, mas
isso era deselegante. À medida que a
lógica do domínio crescia em complexidade,
tornava-se muito difícil trabalhar com
este código:
· embutir lógica
nas telas facilitava a duplicação
de código, o que significava que alterações
simples podiam resultar em buscas de código
semelhante em muitas telas.
· a existência
de lógica de domínio nas telas
dificultava as alterações na interface
com o usuário (por exemplo, a migração
de uma interface cliente do tipo desktop para
a web).
Uma alternativa era colocar a lógica
de domínio no banco de dados na forma
de procedimentos armazenados (clientes magros).
No entanto, os procedimentos armazenados usavam
linguagem proprietária o que eliminava
a possibilidade de migração entre
diferentes fornecedores de SGBDs.
A resposta para o problema da lógica
de domínio veio então da comunidade
OO: migrar para um sistema em três camadas.
Nesta abordagem você tem uma camada de
apresentação para a interface
com o usuário, uma camada de domínio
para a lógica de domínio e uma
camada de acesso a dados. Desta maneira você
pode tirar toda a complexa lógica de
domínio da interface com o usuário
e colocá-la em uma camada onde é
possível estruturá-la apropriadamente
utilizando objetos.
|



